



Si el problema es demasiado difícil, rendirse de inmediato – Desde dentro
Las máquinas no creen que sea una ilusión. No lo decimos, un grupo de investigadores de Apple que acaban


Las máquinas no creen que sea una ilusión. No lo decimos, un grupo de investigadores de Apple que acaban de publicar un estudio informativo con el título (» (»La ilusión del pensamiento‘). En él, estos expertos analizaron el rendimiento de varios modelos de IA con la capacidad de proporcionar «razón», y sus conclusiones son sorprendentes … y preocupantes.
Ridantes de la «razón». Lo normal cuando se evalúa la capacidad de un modelo AI es usar puntos de referencia con programas o pruebas de matemáticas. En cambio, Apple creó varias pruebas basadas en rompecabezas lógicos que eran completamente nuevos y, por lo tanto, no podían ser parte del entrenamiento de estos modelos. Claude Thinking, Deepseek-R1 y O3-Mini participaron en la evaluación.
Modelos que se bloquean. En sus pruebas Ellos verifican Al igual que todos estos modelos de argumentación, vinieron contra una pared con bruces cuando tenían problemas complejos. En estos casos, la precisión de estos modelos recurrió al 0%. Tampoco se acordó que les habían dado a estos modelos más recursos si intentaban resolver estos problemas. Si fueran dificultades, no pudieron con ellos.
Lo pensarás. Algo curioso realmente sucedió. Cuando los problemas se volvieron más complicados, estos modelos ya no comenzaron a pensar. Usaron menos tokens para resolverlos y resolverse antes de poder usar recursos ilimitados.
No con ayuda. Los investigadores de Apple incluso intentaron dar a los modelos un algoritmo exacto que dirigía a los modelos que encontraran el paso a paso. Y aquí, otra sorpresa de capital: ninguno de los modelos logró resolver problemas a pesar de que tenían soluciones guiadas. No podían seguir constantemente las instrucciones.
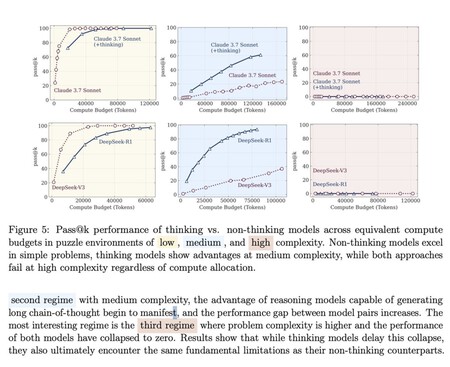
Tres tipos de problemas. En su evaluación, dividieron los problemas que se resolverán en tres clases y verificaron si los modelos de argumentación realmente contribuyeron a los modelos tradicionales que no hacen «razón».
- Problemas con baja complejidad: los modelos de argumento han excedido efectivamente a aquellos que no tenían esta capacidad de argumentación. Por supuesto, a menudo piensan demasiado para resolver estos problemas simples.
- Problemas promedio de complejidad: todavía había una ventaja sobre los modelos convencionales, pero no demasiado.
- Problemas de alta complejidad: todos los modelos con estos problemas.
No creo nada. Según estos investigadores, la razón de esta falla es simple cuando se trata de justificación en problemas complejos. Estos modelos no «justifican» en absoluto y solo usan técnicas avanzadas de reconocimiento de patrones para resolver problemas. Esto no funciona con problemas complejos, y los conceptos básicos de estos modelos se desmoronan por completo. En vista de estos problemas, si un modelo recibe instrucciones claras y puede mejorar e intentar resolverlos más recursos, este estudio muestra algo diferente.
Lejos de agi. Estos resultados sugieren que la expectativa que estos modelos han creado no se merecen: los modelos de argumentación actual simplemente no cambian una cierta barrera agregando datos o computación. Algunos señalaron cómo los modelos de argumentación podrían ser una posible forma de buscar AGI, pero las conclusiones de este estudio muestran que en realidad no estamos más cerca de alcanzar modelos que pueden verse como inteligencia artificial general.
No encontrará soluciones, notará y copiará. De hecho, el estudio confirmó algo que otros defendieron en el pasado: estos modelos simplemente tienen conocimiento y reproducen la solución que ya habían aprendido al memorizar cuando encuentran los patrones correspondientes que conducen a esta solución. Por lo tanto, estos modelos podrían ser el famoso problema del Torres de hanoi De muchos movimientos porque saben que la solución se puede usar sistemáticamente. En otros, sin embargo, fallaron los pocos movimientos.
Loros estocásticos. Muchos de los críticos de la IA siempre Has defendido Que los modelos generativos, la razón o no, son básicamente loros que repiten lo que se enseñó. En el caso de la IA, puede ver patrones y puede encontrar/predecir la siguiente palabra/píxel al crear texto o imágenes. El resultado suele ser convincente, pero solo porque se han vuelto extremadamente buenos cuando reconocen estos patrones y reaccionan correctamente y coherente. Pero no hay un nuevo conocimiento: la quya se repite.
No piensas. Otros expertos críticos de estas expectativas nos han hecho conscientes de hacernos conscientes de los peligros del antropomorfismo de IAS. Lo expliqué Subbarao Kambhampti de la Universidad de Arizona, que, por ejemplo, analizó el «proceso de argumentación» de estos modelos y su «cadena de pensamiento». Usamos verbos como «pensar» si no piensas. No entienden lo que hacen, y eso contamina todos los supuestos que hacemos sobre su capacidad (o falta de ella).
No confíes en lo que te dice la IA. El comportamiento de estos modelos confirma lo que se sabe porque ChatGPT apareció en el sitio. Entonces convencen de que estos modelos «razonan» o no: la realidad es que pueden cometer errores graves y cometer errores, aunque otros ciertamente son correctos. De hecho, hay casos en los que estos modelos sorprenden a través de su capacidad para resolver problemas: En el científico americano Un grupo de matemáticos fue superado por un modelo de IA que logró resolver algunos de los problemas matemáticos más complejos que no pudieron resolver o que tardaron más en resolver.
Imagen | Tipo de rompecabezas
En | Copilot, ChatGPT y GPT-4 han cambiado el mundo de la programación para siempre. Esto se piensa en programadores





{kind=link}