



Alibaba presentó su modelo de IA más grande con mil millones de parámetros. La pregunta es si eso significa algo en este momento – Desde dentro
El gigante chino Alibaba ha anunciado un nuevo modelo de voz, el más grande que ha anunciado hasta ahora.

El gigante chino Alibaba ha anunciado un nuevo modelo de voz, el más grande que ha anunciado hasta ahora. Se llama Qwen-3-Max y sospecha que tiene más de mil millones de parámetros.
El mejor. Es el último modelo dentro de la serie QWEN3 que se lanzó en mayo de este año y, como dice el nombre ‘Max’, es el más grande hasta ahora. Su tamaño resulta de los parámetros para ser de mil millones para ser precisos, mientras que los modelos anteriores en su serie alcanzaron un máximo de 235,000 millones. Respectivamente Post de la mañana del sur de China (Que propietario Alibaba), su modelo se destaca en la comprensión del lenguaje, el argumento y la generación de texto.
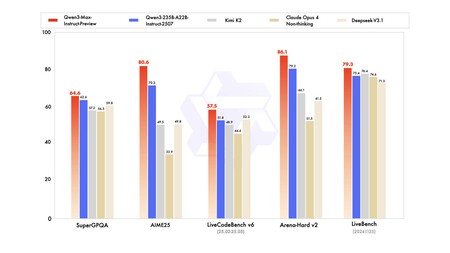
Puntos de referencia. Los resultados de los puntos de referencia presentan QWEN3-Max frente a competidores como Claude Opus 4, Deepseek V3.1 y Kimi K2. Si Gemini 2.5 Pro o GPT-5 no aparecen, esto se debe a que estos son modelos de los argumentos y solo compararon modelos de reacción rápida. Como tú en relación con Dev.ToTanto Gemini 2.5 Pro como GPT-5 logran puntajes más altos en matemáticas y código, por lo que los modelos de argumentación en estas áreas aún tienen ventajas. Vista previa de Qwen3-Max ya se puede probar gratis.
parámetro. Los parámetros son todas variables internas que un modelo aprende durante la capacitación. En otras palabras, es el conocimiento que el modelo ha recibido de los datos con los que ha entrenado y le permite interpretar nuestras consultas y generar sus respuestas. En teoría, el modelo tiene más y mejores habilidades. Esto también implica que necesita más potencia informática para entrenar y llevar a cabo el modelo.
Más no significa mejor. El discurso de los parámetros recuerda el de los megapíxeles con las primeras cámaras. Un sensor de 100 megapíxeles toma fotos más grandes que un sensor de 10, pero hay otros factores decisivos que influyen en la calidad de la imagen, como: B. Tamaño del sensor o luz de lente.
Datos de calidad. Otros parámetros pueden traducirse a más capacidad de aprendizaje y una mayor resolución de tareas complejas siempre que se hayan utilizado datos de entrenamiento de alta calidad. Es obvio: un modelo de voz que ha sido entrenado con datos redundantes, falsos o sesgados, aprende y reproduce estos errores en su empresa.
Hay más. El laboratorio en 2022 Profundo de Google, descubierto que muchos modelos en parámetros eran de gran tamaño, pero se subrayaron en los datos. Para demostrarlo, crearon el modelo de chinchilla con «solo» 70,000 millones de parámetros, pero cuatro veces más datos. El resultado fue que Gopher lo derrotó, un modelo con cuatro veces más parámetros.
arquitectura. La arquitectura del modelo es otro factor crucial para lograr un modelo eficiente. Una arquitectura estándar no es la misma, lo que obliga al modelo a usar toda su red neuronal que una como una como una Mezcla de expertos Esto consiste en muchas redes más pequeñas. Sería algo así como un comité de expertos con una especialidad. De esta manera, el modelo puede seleccionar a sus expertos para cada consulta y no tiene que usar toda la red. Por ejemplo con esta tecnología, Mistral logra usar solo una fracción de sus parámetros Y así es más rápido y barato de hacer.
Imagen | Markus Winkler sobre Pxels
En | La alianza Mistral ASML revela el Plan E Europeo B: si no podemos producir chips, al menos controlaremos cómo se hacen





{kind=link}